A case study in how “AI support” fails the moment it actually matters. This article documents the loss of a critical ChatGPT workspace conversation through backend failure, followed by a support process that denied reality, looped incompetently, and ultimately could not accept its own diagnostic evidence. It exposes systemic fragility, misplaced corporate faith in “Copilot”, and why treating LLMs as reliable infrastructure, especially in regulated environments, is reckless.
Contents
- Contents
- 1. Introduction
- 2. The Failure: “Unable To Load Conversation”
- 3. Phase 1: The Denial Of Reality
- 4. Phase 2: Support Theatre
- 5. Phase 3: Kafka, But With HAR Files
- 6. The Core Problem: ChatGPT Cannot Handle Its Own Complexity
- 7. The Irony Is Brutal
- 8. Conclusion: A Simple Recommendation (For Adults)
- 9. Coda: And This Is Before We Even Get To The Real Problems
1. Introduction
I recently lost a substantial, important ChatGPT conversation.
Not because I deleted it.
Not because I changed accounts.
Not because I misunderstood how links work.
I lost it because ChatGPT broke itself, and then spent a solid hour gaslighting me about it.
This is an account of how a supposedly state-of-the-art AI system fails at the most basic requirements of a serious tool: data integrity, accountability, and support that works when something goes wrong.
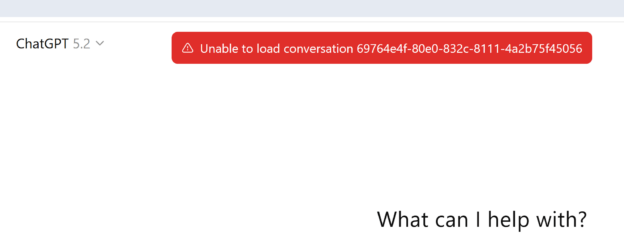
2. The Failure: “Unable To Load Conversation”
The error message is admirably concise:
Unable to load conversation.
No error code.
No remediation guidance.
No explanation of whether the data still exists.
Just a dead conversation ID, belonging to my account, my workspace, my branched thread, and a shrug.
This was not an edge case. The conversation had:
- multiple branches,
- significant length,
- and prior instability in the same root branch.
In other words: exactly the kind of conversation ChatGPT encourages you to use it for, extended reasoning, iterative thinking, and serious work.
I am acutely aware that this is a single incident. Unfortunately, it is not an isolated one. Variants of the same failure, “Unable to load conversation”, missing threads, unrecoverable workspaces, have been reported consistently over several years, particularly in long-running or heavily branched conversations.
The common factor is not user error, but complexity at exactly the point the product encourages serious use. To be clear, this experience was not rescued by plan tier, workspace context, or nominal support escalation, the failure mode is architectural, not contractual.
3. Phase 1: The Denial Of Reality
I did what any reasonable user would do: asked ChatGPT what was going on.
The response was a masterclass in confident wrongness:
- “That’s a shared link issue.”
- “You’re probably logged into the wrong account.”
- “That format isn’t meant to be accessed.”
- “This is normal behaviour.”
None of these were true.
This was my conversation.
In my workspace.
Accessible previously.
Branched intentionally.
At no point did the system say:
“Yes, this looks like a backend failure.”
Instead, it defaulted to the oldest sin in tech support: assume the user is confused.
4. Phase 2: Support Theatre
Eventually, I reached “support”.
Or rather: an AI pretending to be support, asking questions whose answers had already been provided.
- What browser?
- What device?
- Have you tried clearing cache?
- Incognito?
- Another device?
Yes.
Yes.
Yes.
Yes.
At this point, the system acknowledged, correctly, that this appeared to be a backend data issue.
Progress! Briefly.
5. Phase 3: Kafka, But With HAR Files
I was then instructed to upload a HAR file for analysis.
Reasonable request. Except:
- The support chat does not accept HAR files.
- It also does not accept ZIP files.
- It fails silently when you try.
- The AI support agent does not know this.
So the loop went like this:
- “Please upload the HAR file.”
- “The interface won’t accept it.”
- “Please upload the HAR file.”
- “It won’t accept HAR or ZIP.”
- “Please upload the HAR file.”
This is not support.
This is a logic bug with a chat UI attached.
Eventually, after renaming files, re-submitting, and explicitly pointing out the tooling failure, the agent claimed the case had been “escalated”.
Whether that means anything remains to be seen.
I am also aware of the usual advice in these situations: wait it out, check status pages, attempt full exports, or hope the data still exists somewhere behind the UI. None of those options address the core problem. If recovery depends on undocumented workarounds, timing, or luck, then the system has already failed as infrastructure.
6. The Core Problem: ChatGPT Cannot Handle Its Own Complexity
Here’s the uncomfortable truth:
ChatGPT is now complex enough to corrupt its own data, but not mature enough to:
- detect that corruption cleanly,
- explain it honestly,
- or support users when it happens.
Branching conversations are powerful, and clearly fragile.
Long-running reasoning threads are encouraged, and apparently unsafe.
Workspaces imply seriousness, but are treated like toys once something breaks.
When a system invites users to think deeply inside it, it assumes responsibility for the durability of that thinking.
ChatGPT works remarkably well as a tool. It fails badly when treated as infrastructure.
Right now, ChatGPT does not meet that bar.
7. The Irony Is Brutal
I used ChatGPT to:
- analyse complex systems,
- reason about resilience,
- and think critically about failure modes.
Then it failed in the most predictable way possible:
- silent data loss,
- opaque errors,
- and an AI insisting everything is “standard behaviour”.
If this were a client system, I would write a post-mortem.
Instead, I’m writing this.
8. Conclusion: A Simple Recommendation (For Adults)
If you are using ChatGPT, or anything built on top of it, for work that matters, here is the only sensible posture:
- Export early. Export often.
- Do not trust long, branched conversations to persist.
- Assume anything you have not copied elsewhere can vanish without warning.
- Treat support as best-effort, not guaranteed.
And let’s deal with the elephant in the boardroom.
If you think you’re “safer” because you’re using Microsoft Copilot, be very clear about what you are, and are not, buying.
Copilot is not a fundamentally different system. It is:
- a wrapper over large language models,
- heavily overlapping with ChatGPT’s behaviour,
- borrowing GitHub Copilot’s tooling context,
- plus some shared or adjacent memory scaffolding.
It is not a magic reliability upgrade because it has a Microsoft logo on it.
I have personally sat in corporate meetings where otherwise intelligent people waved away legitimate risk with the phrase:
“It’ll be fine… it’s Copilot.”
This is not reassurance. It is cargo-cult thinking.
If ChatGPT can:
- silently lose conversations,
- corrupt long or branched reasoning threads,
- fail to surface backend errors clearly,
- and route users into support loops that literally cannot accept the diagnostic files they request,
then you should assume any product built on the same foundations can fail in analogous ways, unless proven otherwise with hard guarantees, not marketing slides.
9. Coda: And This Is Before We Even Get To The Real Problems
Everything described above is purely about data durability and platform reliability.
It is before:
- hallucinations,
- confident fabrication,
- subtle but critical errors,
- topic drift,
- invented citations,
- or the broader cognitive dissonance that emerges when probabilistic text generation is treated as authoritative reasoning.
These are not edge cases. They are structural properties of the technology.
So when someone suggests piping AI-generated output directly into regulated financial services platforms, production decisioning systems, or compliance-sensitive workflows, the correct technical response is not optimism.
It is: absolutely fucking not; not without controls, validation, and independent verification.
If that sounds cautious, good.
If it sounds unfashionable, even better.
It becomes genuinely dangerous when combined with how organisations are currently approaching AI adoption in regulated environments. The prevailing focus on uptake, exemplars, and visibility, rather than data lifecycle, control boundaries, and accountability, actively amplifies the risk exposed here.
That broader governance failure is explored in a companion piece: “When Adoption Becomes The Goal, Risk Becomes Invisible By Design“.
Because the systems we regulate, audit, and depend on for real-world consequences do not care how persuasive a model sounds, only whether it is correct, durable, and accountable.
Right now, large language models are impressive tools.
They are not trustworthy substrates.
Act accordingly.